
Behind the Scenes: Drupal's Footprint in Top Universities

By
When Kevin suggested exploring Drupal usage among top universities, I initially thought it would be a straightforward task with most information readily available online. However, getting into the task revealed its complexity. The challenges ranged from selecting an appropriate university ranking system to finding websites beyond the primary university site.
Here is a walk-through of the steps we followed, with code examples and the tools we used in this exercise.
Step 1: Choosing the Right University Ranking
Our first task was to decide which global university ranking system would provide the most accurate data. We reviewed three major systems: Edurank, Times Higher Education, and QS (Quacquarelli Symonds). After careful consideration, we selected QS World University Ranking due to its longstanding reputation and popularity. Additionally, we also included the Times Higher Education Ranking in the data.
Step 2: Compiling University Data
We began by copying the names and locations of the top 300 universities from the QS world ranking. Since QS didn't provide URLs, we turned to Klaus Förster’s comprehensive list of 9,893 universities. The challenge we faced was in mapping the URLs with the university list. There were differences in the names on both lists, so full-text matching was not possible. To match the university names from QS with those in Förster's list, we developed a simple Python script using the fuzzywuzzy module, which efficiently mapped the URLs for 200 universities. The remaining URLs were added manually.
#https://github.com/zyxware/technology-parser/blob/main/unimap.py
def find_best_match(name):
best_match, score = process.extractOne(name, uni_to_url.keys(), scorer=fuzz.token_sort_ratio)
return uni_to_url[best_match] if score >= threshold else NoneStep 3: Discovering and Cleaning Subdomains
Identifying the numerous websites hosted by universities, beyond their primary sites, was a significant challenge. We used Sublist3r to gather subdomains with open ports 80 or 443.
sublist3r -d www.example.com --ports=80,443We then used puredns to filter out non-resolving domains. A cleanup process was necessary to remove subdomains like 'www', 'mail', 'dev', etc. After cleaning, we had approximately 126,000 domains ready for technology assessment.
puredns resolve domains.txt --write valid_domains.txt#https://github.com/zyxware/technology-parser/blob/main/filter_url.py
# Define the keywords to filter out
keywords = ['mail', 'image', 'login', 'autodiscover', 'microsoft', 'googleapis', 'google', 'amazon', 'cdn', 'vpn', 'cisco', 'mx', 'spam','aws', 'idp', 'smtp', 'cloud', 'stage','dev']
# Function to check if any keyword is in the URL
def contains_keyword(url, keywords):
return any(keyword in url for keyword in keywords)Step 4: Technology Detection with Wappalyzer
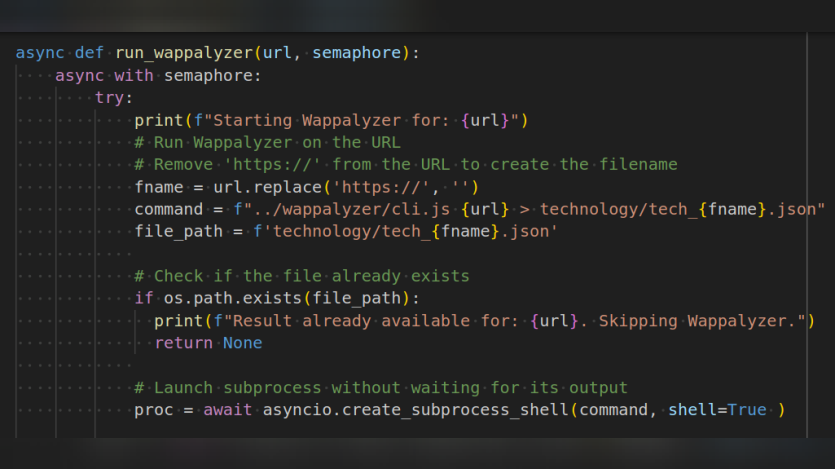
For technology detection, we utilized Wappalyzer to scan all identified subdomains. I developed a simple script to run the wappalyzer proceses in parallel with an option to resume operation if frozen. Completing the scan on 126,000 domains took about 6-8 days.
Wappalyzer was able to detect technology only for a subset of domains, as the checking wasn't very rigorous, and the timeout was set to a low number to maximize the number of domains checked in less time. From this process, we identified approximately 9,000 Drupal websites.
#https://github.com/zyxware/technology-parser/blob/main/wap.py
async def run_wappalyzer(url, semaphore):
async with semaphore:
try:
print(f"Starting Wappalyzer for: {url}")
# Run Wappalyzer on the URL
# Remove 'https://' from the URL to create the filename
fname = url.replace('https://', '')
command = f"../wappalyzer/cli.js {url} > technology/tech_{fname}.json"
file_path = f'technology/tech_{fname}.json'
# Check if the file already exists
if os.path.exists(file_path):
print(f"Result already available for: {url}. Skipping Wappalyzer.")
return None
# Launch subprocess without waiting for its output
proc = await asyncio.create_subprocess_shell(command, shell=True )
# Wait for the process to complete and return its exit status
await proc.wait()
if proc.returncode == 0:
print(f"Wappalyzer completed successfully for: {url}")
return url
else:
print(f"Wappalyzer encountered an error for: {url}")
return None
except Exception as e:
print(f"Error running Wappalyzer for {url}: {e}")
return NoneStep 5: Extract CMS details to a CSV file
The wappalyzer output was stored in a folder with all the details it generated. I created a Python script to extract CMS details for each subdomain, generating a CSV file that served as the foundation for our final spreadsheet.
#https://github.com/zyxware/technology-parser/blob/main/tech_parser.py
def create_csv(base_domains_file, folder):
base_domains = read_base_domains(base_domains_file)
tranco_series = load_tranco_data('tranco_Z25PG.csv')
domains_data = {}
for filename in os.scandir(folder):
if filename.is_file():
for base_domain in base_domains:
if filename.name.endswith(f"{base_domain}.json"):
full_domain = filename.name.split('.json')[0][5:] # Removes 'tech_' prefix
domains_data.setdefault(base_domain, []).append((full_domain, filename.name))
with open('domains.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['BaseDomain', 'FullDomain', 'URL', 'CMS', 'Version', 'TrancoRank'])
for base_domain, files in domains_data.items():
for full_domain, filename in files:
full_path = os.path.join(folder, filename)
if os.path.exists(full_path):
cms_data = get_cms_data(full_path)
tranco_rank = find_tranco_rank(full_domain, tranco_series)
writer.writerow([base_domain, full_domain] + cms_data + [tranco_rank])
else:
writer.writerow([base_domain, full_domain, 'File Not Found', 'File Not Found'])Conclusion
The full code used in this project is available in this repository. Note that the code is very specific to our needs and may require modifications for use in similar projects.
We can now confidently state that 80% of the top 100 universities use Drupal. However, we need your support to make this study as comprehensive as possible. We have published the complete data in a Google Sheet and created a survey to fill in the identified gaps. Please share this with your friends or colleagues at the universities mentioned in this study and kindly request them to fill out the Google form. This will help us gather data on CMS information that could not be found.
Also read: Drupal Usage in Top Universities Worldwide: A Progress Report and Seeking Support








