
Drupal.org Outage Resolved After Brief Downtime


The Drupal.org website experienced a brief outage recently, causing the site to be down for a few hours. During the downtime, Fran Garcia Linares communicated with users via a Slack group, stating,
"We’ve identified the issue and we’re working on bringing the services back up."

The Drupal team promptly addressed the issue, and the site was restored within a short span. Though the primary server was still down when this report was first filed, the load was swiftly shifted to a secondary server, and the issue was satisfactorily addressed, making the website fully operational. The reason for the primary server's failure is still under investigation, and we have yet to get an update on it.
Apart from Fran, Neil Drumm, Drupal Architect at D.A., and Narayan Newton, Lead Performance Engineer at Tag1 Consulting, helped resolve the issue.
I'm very grateful to the DA staff who responded to the alerts: Fran Garcia-Linares and Neil Drumm—as well as Narayan Newton from Tag1Consulting who resolved this issue, and who help us manage, maintain, and upgrade our infrastructure in general.
We currently run a hybrid infrastructure of virtual machines hosted at the Oregon State University Open Source Lab and a fully modern, k8s-based infrastructure at AWS, a transition which Tag1 Consulting has been managing on our behalf.
Tim Lehnen, CTO of the Drupal Association, responded to The Drop Times in a conversation with Ben Peter, our Community Manager.
The site and the Packagist repository were down for almost an hour.
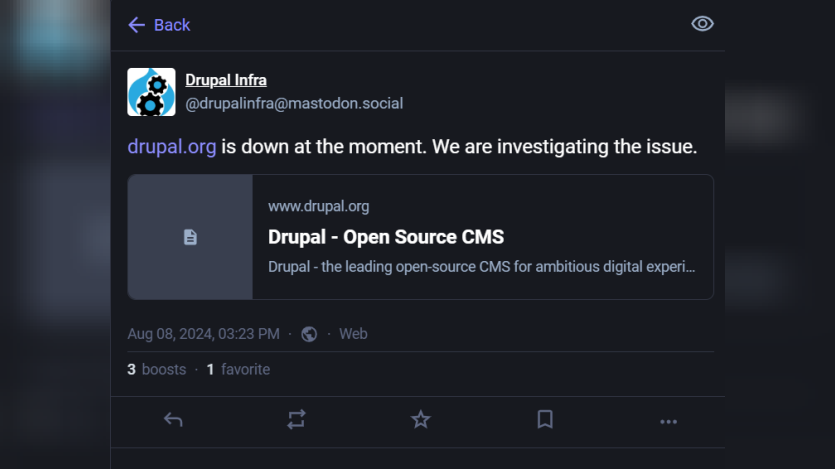
Earlier, Tim commented on a LinkedIn post by Grzegorz Pietrzak about the outage, briefly explaining the scenario.
Speaking with my Drupal Association CTO hat on - a quick update on what happened:
From ~09:23 UTC / 2:23 am Pacific to ~10:29 UTC / 3:29 am Pacific, Drupal.org experienced an outage. The failure was related to Drupal.org’s high-availability media server pair, which hosts files for our sites. Unfortunately, the primary server in the pair experienced a partial failure, which took down services, but the secondary was not able to take over. To resolve the issue, we were able to manually fail-over to the secondary.
We are currently still running on the secondary and will perform a post-mortem on the primary.
Users are encouraged to follow the Drupal community channel on Slack for any further updates or information.
PS: This is a growing story, and we will be adding more details as the investigation brings in new information. Stay tuned. /Editor
Image Attribution Disclaimer: At The Drop Times (TDT), we are committed to properly crediting photographers whose images appear in our content. Many of the images we use come from event organizers, interviewees, or publicly shared galleries under CC BY-SA licenses. However, some images may come from personal collections where metadata is lost, making proper attribution challenging.
Our purpose in using these images is to highlight Drupal, its events, and its contributors—not for commercial gain. If you recognize an image on our platform that is uncredited or incorrectly attributed, we encourage you to reach out to us at #thedroptimes channel on Drupal Slack.
We value the work of visual storytellers and appreciate your help in ensuring fair attribution. Thank you for supporting open-source collaboration!

ASK: Drupal Community Needs Your Support
View all →
Disclosure: This content is produced with the assistance of AI.
Note: The vision of this web portal is to help promote news and stories around the Drupal community and promote and celebrate the people and organizations in the community. We strive to create and distribute our content based on these content policy. If you see any omission/variation on this please reach out to us at #thedroptimes channel on Drupal Slack and we will try to address the issue as best we can.

Related Organizations
Related People





You may also like
















