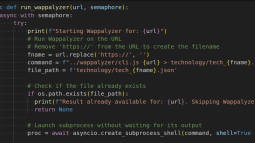
Scraping Content in Drupal: Simplifying Data Migration


Gerardo Cadau from Octahedroid provides a detailed guide on scraping content from HTML sources in Drupal, aiming to facilitate data migration from Drupal 7 to Drupal 10. This blog post explains using Drupal's serialization capabilities to extract data for web migrations. The techniques include employing specific Drupal plugins to handle the extraction and reformatting of data, ensuring that transitions to the newer Drupal platform maintain data integrity and functionality. This approach is critical for websites updating to the latest Drupal version to leverage its enhanced features while retaining existing content structures.

ASK: Drupal Community Needs Your Support
View all →
Disclosure: This content is produced with the assistance of AI.
Disclaimer: The opinions expressed in this story do not necessarily represent that of TheDropTimes. We regularly share third-party blog posts that feature Drupal in good faith. TDT recommends Reader's discretion while consuming such content, as the veracity/authenticity of the story depends on the blogger and their motives.
Note: The vision of this web portal is to help promote news and stories around the Drupal community and promote and celebrate the people and organizations in the community. We strive to create and distribute our content based on these content policy. If you see any omission/variation on this please reach out to us at #thedroptimes channel on Drupal Slack and we will try to address the issue as best we can.

Related Organizations
Related People


You may also like