
Pantheon Content Publisher: Working Back to the Roots of Innovation



In a virtual discussion with The DropTimes Editor-in-Chief Sebin A. Jacob, Chris Yates, Vice President of Product Management at Pantheon, and Roland Benedetti, Senior Director of Product Management, shared insights into Pantheon Content Publisher, a new tool designed to simplify web publishing workflows. Built to connect Google Docs directly with platforms like Drupal, WordPress, and Next.js, this tool aims to make the transition from content creation to publication seamless and efficient.
The conversation highlighted how Pantheon Content Publisher bridges the gap between traditional content management systems and modern content creation tools. Chris and Roland discussed how it helps writers and editors by integrating familiar tools like Google Docs, while also ensuring compliance, accessibility, and editorial governance. Key features like AI-driven content enhancements and smooth integration with existing workflows were a central focus.
The discussion also touched on broader themes, including the future of content operations, the tool’s ability to handle multi-language content, and plans for integration with other platforms like Figma. Pantheon’s vision is clear: to simplify publishing processes while empowering teams to focus on creating great content.
TDT [1]: This feels like a new era of publishing, which I gather from the content you’ve already shared on social media. Let me historicise it a bit. I started working in publishing around the late 1990's-early 2K's. Back then, I was using Macromedia Dreamweaver. At the time, I was working with a web portal that offered digital version of a print newspaper. The process involved taking the newspaper pages created in Adobe PageMaker—this was before InDesign existed—and transferring them to Dreamweaver (Adobe had yet to eye Dreamweaver).
We had to manually extract the stories from PageMaker, edit them for the web, and painstakingly layout them into web pages. As there were no UNICODE fonts available then, considering our language was not in the ASCII encoding, we had to do font conversions which were error-prone that prompted us to do some typesetting as well. Only someone who works with a non-European language that does not use Latin glyphs to represent their letters would be able to comprehend the amount of work here, as we had to hack the ASCII fonts, replace the glyphs while not being able to assign unique values for the base consonants and vowels. In a computing standpoint, those were junk. It produced data that was not searchable or sortable. Still the webpages should work. Hyperlinks should work. It should be human readable. Although, there were some basic templating available, essentially, we were publishing new web pages and building a fresh home page from scratch, each night. We would then pull the individual stories and hard link them to the titular blocks in homepage. That entire process changed with the advent of content management systems (CMS).
After the CMS revolution, another shift has occurred. Today, many websites take content from outside their primary work environment. I am not even talking about social media where crowdsourced content is curated, but about content rich websites by genuine content producers such as newspapers, magazines, clubs, and organisations. Typically, collaboration happens in Google Docs, where all the iterations and edits are made first. Then, the final content must be moved manually into the CMS. This creates a significant hurdle in the web publishing workflow.
Pantheon Content Publisher seems to be bridging this gap, offering a way to streamline the process. Could you elaborate further on how this works?
Chris Yates: It seems like we have some things in common—you, Roland, and I. Between the three of us, we probably have about 75 years of experience in the web and CMS industry.
I also started in newspapers in the late 1990s. Back then, I was working with Vignette StoryServer. Remarkably, the workflows to get content from creation to publication haven’t changed as much as you’d think in 25 years. In those days, we would cut and paste content from our editorial system—designed for producing printed pages every morning—into Vignette or some middleware we had developed to get it onto the web eventually.
The process was often inconsistent, error-prone, and time-consuming. Over the years, CMSs have evolved with features like in-place editing, WYSIWYG text fields, and many other advancements. But as you pointed out, the core editorial workflow remains largely the same: people create content in one place and publish it in another.

The genesis of Content Publisher stems from our attempt to solve these ongoing issues. Much like how Pantheon was created by founders from the Drupal community to streamline building websites and focus on delivering great results rather than managing infrastructure, Content Publisher emerged from our need to address inefficiencies in our own workflows. As a company rooted in Drupal but also running WordPress in various contexts, we found ourselves using a disconnected workflow. Authors created content, collaborated in Google Docs, and made edits and suggestions. However, the content was copied and pasted manually into Drupal at the end of the process. This approach is far from seamless.
This disconnection creates challenges. For instance, if you need to revisit and edit content, you must access the CMS and ensure everything stays in sync. Content Publisher was designed to bridge this gap between content creation and publication while also adding new capabilities.
Publishing isn’t just about pressing a button; it involves enhancing the content, integrating it with other elements in your library (like media, author profiles, or related items), adding metadata, and ensuring it aligns with the broader content architecture. It’s not just about moving text—the content needs to be interconnected with the rest of the publishing system to ensure discoverability and cohesion.

Roland Benedetti: What you both said about the publishing workflow not changing much is absolutely true, and I completely agree. However, one thing that has changed significantly is the tools people use for authoring. These tools have evolved dramatically.
I remember 20 years ago, when I worked with a previous CMS vendor. We tried to integrate Microsoft Word (which wasn’t cloud-based at the time) with XML. We thought it was a great way to get started, but while the idea was sound, the tools simply weren’t ready for it.
The biggest change today is the collaboration aspect and the rise of cloud-based authoring tools. Google Docs, for example, has made incredible progress. It’s no longer like PageMaker, which was designed for print and very much looked the part. Tools like Google Docs now offer features such as pageless mode and tabs, making them less print-focused and more collaboration-centric. CMS vendors have attempted to incorporate collaboration features into their platforms, but honestly, tools like Google Docs do it best. And it’s not just Google Docs—other tools like Notion and Monday have also become prominent, especially for managing tabular data.
Our first integration is with Google Docs, and the next one will likely be with Google Sheets, as it makes perfect sense for many workflows. Our vision is to create a content operation workflow system. I intentionally avoid calling it a CMS because our goal is to meet users where they work, integrating with the tools they already rely on.
TDT [2]: Are you saying, you will integrate Google Sheets? When integrating spreadsheets, one major problem is the load time on the browser because sheets can be heavy, especially with embedded graphs. How will you handle this?
Chris Yates: That’s a great question. The way we’re approaching this is not like SharePoint, where Office Docs were just put on the web as-is. We’ve created a platform that ensures stability in terms of markup and design. Instead of letting everything look inconsistent, we filter content through a system that ensures a consistent expression of the content on the website.
For Google Sheets, rather than dumping a spreadsheet onto the web, we aim to represent the data in a visually appealing, structured way—like a tiled layout for case studies. This ensures governance around how the content is presented.
Roland Benedetti: If I can add to that, the idea is to use Google Sheets as a backend for authoring, not to move Sheets directly to the web. Google Docs is great for long-form editorial content, while Sheets works well for structured data, like directories or listings. We want governance to ensure Sheets content isn’t exposed directly but instead goes through a workflow before publication.
TDT [3]: The reason I asked this is because we’ve published stories with Venn diagrams and pie charts created in Sheets. We had to take screenshots and upload them because embedding them directly was too bandwidth-intensive.
Chris Yates: In our Google Docs integration, you can include graphs created from Sheets in your body copy, and we emit them as images rather than objects to save bandwidth to consume, which falls into your design system. The image will have rounded corners if your design system has rounded corners. If you're using Pantheon's AGCDN or our IO optimizer, it can automatically be converted to a Webp.
So it becomes really an image that is accessible. It can have alt tags, it can have titles, it can have all of those things, and to your point, it's not, if that data updates, you don't necessarily want it to update immediately on the web; you'd probably want to have a process by saying, oh yeah, I actually do want to say, move the charts and graphs around, or the bars were changed.
It's really about setting the, updating from the source data, and then republishing that content. So there's always a notion of, much like how code works in Pantheon, where you have a dev-test and live environment, and today, we have an unpublished and a published state for content. So you can keep working on content in Google Docs or a sheet and not have that just change live on the web instantly. Because people want to be deliberate about when they publish it, who approves it, and those sorts of things.
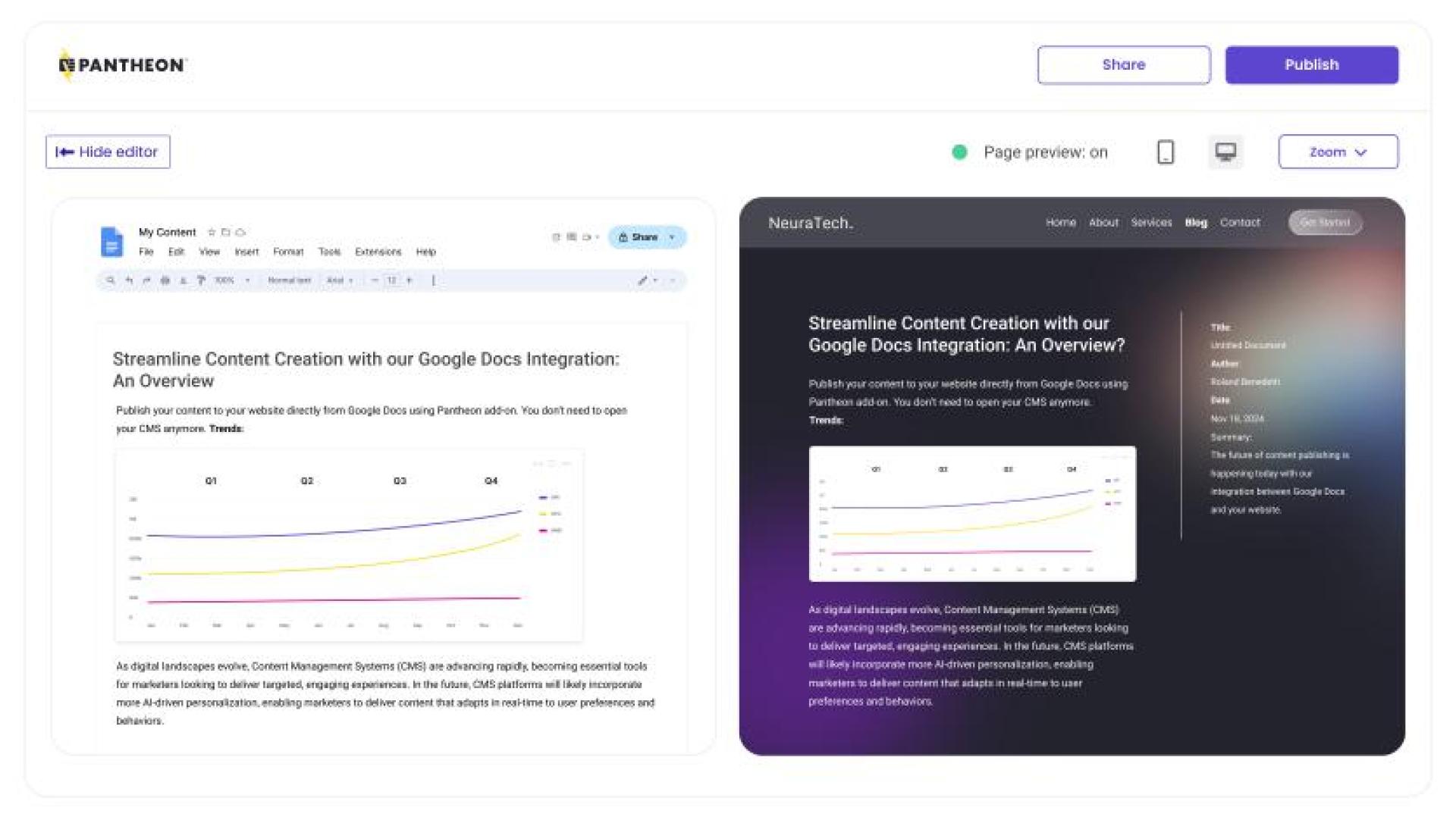
TDT [4]: One question I had is about the tools we use for content editing. For instance, in WordPress, we use Gutenberg, and in Drupal, we use CKEditor. Before that, we used TinyMCE. Will these tools still remain in use, and will Google Docs push content to whichever system the CMS is using? Is that the concept?
Chris Yates: What we focused on first is long-form content, which makes up a significant portion of what’s on the web. Much of the content on websites falls into this category.
It doesn’t have to mean essays or extensive blog posts but pages such as About Us, investor pages, news snippets, and podcast episodes. These typically include metadata, images, and text, making them ideal for our current situation.
There are still valid use cases for WYSIWYG editors that operate within a field. For example, Gutenberg—which works at the page level—or tools like paragraphs in Drupal, which support page building with embedded WYSIWYG functionality. These tools allow users to easily add hyperlinks, insert inline images, or include similar elements.
I see 'Content Publisher' as a complementary solution at this stage. Websites today are often described as "composable," but I think of them as "composite," where different tools are suited to different parts of the website. For example:
- Homepages: Tools like Gutenberg or paragraphs might be used to create specific layouts.
- Programmatically generated pages: Product detail pages are a good example, as they are typically generated entirely from database metadata.
- Content-rich pages: Marketers, editors, and writers often want to be more closely involved in the publishing process. Content Publisher works well for these cases.
Content Publisher is not designed to replace every tool in a web team’s toolkit. Instead, it is designed to complement existing tools, whether they are in Drupal, WordPress, or Node.js-based frameworks. It provides a better solution for specific use cases while coexisting with other tools.
TDT [5]: Is the Content Publisher primarily meant for text? What about if we have images and videos inside the document?
Roland Benedetti: It’s not made primarily for text; it’s designed for long-form content with an editorial focus. That’s where it shines the most. However, you can also embed media, assets, and interactive components.
One particularly interesting feature, especially from a Drupal integration standpoint, is the concept of smart components. These are elements you can embed inline within the flow of your document, which in the Drupal ecosystem corresponds to a single directory component. For example, if you’re writing a product marketing review and want to include a card with the product details, price, and a "Buy Now" action, this content doesn’t belong directly in the editorial text. Instead, it’s embedded within the flow of the article but is linked to a component that resides elsewhere on your website. This is what smart components enable.
In this way, we add structure and functionality, seamlessly embedding media and components within the document’s flow. Additionally, we leverage generative AI to enrich documents. This includes adding textual information like summaries, descriptions, tagging, and entity extraction. It can also involve enriching documents with media, where AI can help source assets far more efficiently than manual methods.
This approach isn’t about being text-only. It’s about managing the entire workflow of writing stories.
TDT [6]: So, one thing—you’re not focusing on complex layouts or interactive elements initially. The primary focus is on long-form articles, but in the future, those types of requirements could also be addressed, right?
Roland Benedetti: Complex layouts are managed on the website through the design system implemented in the delivery layer. I’m not saying we don’t support this at all—in fact, we do support it in many ways.
However, it’s not part of the same workflow. For instance, Google Docs allows you to define and provide structured metadata, enabling you to control the layout. You can do the same with Content Publisher. You can enrich your story with metadata, which can be used for layout purposes.
To be clear, we are not a layout system. Instead, we provide the content and data that Drupal can use to manage the layout effectively.
TDT [7]: Does Content Publisher support multi-language content creation and publishing? Specifically, will it include language-specific formatting and localization features?
For example, I speak an Indic language called Malayalam, and in some of the portals I worked with, the content is created in both English and Malayalam. On another, Hindi too was there. Since there were no translation systems available, we had to handle translations manually.
Will this platform include any tools to assist with such tasks?
Roland Benedetti: That’s a very good question. Our approach here is to remain agnostic and neutral. We don’t want to take an overly opinionated path. To be clear, Google Docs is capable of handling multi-language content, and we want to support that capability without enforcing a specific workflow.
For example, if someone wants to use Google Docs with tabs for different language versions, they can do that with Content Publisher. If they prefer to manage localization in a completely different way, they can do that as well. While we don’t have an integrated model for managing localization, we aim to support structured content, including localized content, without dictating how it should be managed.
We’ve observed many different ways of handling localization, and we believe it’s better to stay open and provide the tools for teams to set up their own workflows. On the front-end side, platforms like Drupal are already well-equipped to manage localization effectively, which is great. Our focus is on properly feeding Drupal the content it needs.
Being connected to the Google Workspace ecosystem also allows teams to choose the tools they prefer for authoring and localization, giving them maximum flexibility and the patterns for localization or translation they want to use. For some teams, this means using tools like Google Translate or other things available from the Google marketplace. For others, it means creating distinct content for different languages.
Even the individual content piece might not exist in both languages because it's really localized and market-specific. From a technical perspective, support for different character sets and so on is built into Google Docs and will kind of push through the content publisher workflow. But instead of saying this is how you do it, I think we've said there are several ways you can integrate the Google Docs user experience.
There are a number of ways you can admit that onto your website, whether it's having a tab to switch languages or a flag to switch languages or having completely different websites because the Drupal community has embraced all sorts of different models based on their particular needs.
TDT [8]: The architecture here is based on REST and GraphQL support, right? In an API-first approach. So are there plans to make the APIs open to third-party developers, so that they can then integrate it with other CMS or DAM platforms or other marketing tools?
Chris Yates: A hundred per cent. The idea is to opt for a modern architecture.
So, we clearly deliver content through the GraphQL endpoint, which means that we can syndicate content not only to Drupal but also to other destinations. And yes, but we don't really have plans now to develop ourselves, the adapter on the other side. I think a lot of things Pantheon has been doing in the past revolve around the idea of open-source communities and so on, as well as leveraging a strong part of the network.
TDT [9]: Okay. So the API is open, isn't it?
Roland Benedetti: Yes.
Chris Yates: Well, it's actually open on both ends. We have the publishing API and have created some tools to help people get started.
We have a Drupal module, a WordPress plugin, and a Next.js SDK. But if you want it to plug into a mobile app written in Swift or whatever, you can plug in your GraphQL client and build whatever you want. On the other side, we have what we call the Ingest API, for which we built the connector from Google Docs into Content Publisher, but we have a partner that's interested in having a Drupal to-content publisher pipeline. As Roland mentioned earlier, we have had some conversations with people who like a notion source for the Ingest. So we have an API that will be open and accessible to partners that want to build in that way and build things that push in the Content Publisher. So then they can get it out into whatever they want on the other end.
TDT [10]: Will users be able to customise the content review process to suit a specific accessibility requirement or SEO-compliance? Will it be a UI-driven process or will it require any coding skills to do that?
Chris Yates: Roland can talk more about it, but some of the AI tools that Roland mentioned are really built into the system. So, we basically have the ability to do things like create tags or suggest titles, suggest summaries, and it's kind of a person-in-the-loop sort of tool.
This is all relevant to SEO and workflow around enhancing content during the publishing process. So, fill in the various pieces of metadata that an SEO expert, marketing, or demand-gen marketing team might want to use to enhance the content.
We already mentioned some of the accessibility stuff based on homogenization or standardization of the content admitted from the API. So rather than having Comic Sans purple 50 points, it admits a markup that can be styled appropriately by a design system that meets the accessibility guidelines that the user or the site owner has set forth, whether it's in their design system or their Drupal theme or whatever.
A lot of you have maybe further longer-term things, thinking about the other things that we could plug in as part of the publishing process.
TDT [11]: When plugging in other things, is there any plan to integrate content publishers with design platforms, maybe Figma or Adobe XD, so you could also streamline the design to development workflow?
Roland Benedetti: Yes, it's kind of another side of the longer-term vision of the tool. I would say probably more Figma than Adobe so far, but what's happening in Figma is a little bit the same as what's happening in Google Docs.
There's like such a strong adoption of Figma that it is the tool where design gets done, but it's also the tool where content can be done sometimes when you think about landing pages and so on. So, I've seen people operating on content in Figma. So we are definitely... but this is more R&D, I would say, at this point, but we are looking into how to bridge and automate because even if there's a lot of work happening in the ecosystem around design systems, it's still very tedious to move design to code to websites.
So, we are investigating different types of automation, from Figma to Content Publisher, to complement the content with the design.
TDT [12]: How does Pantheon plan to handle versioning or synchronization when both content and code are updated simultaneously, especially in complex projects involving multiple stakeholders? Or what's the plan to handle versioning of a document and synchronization of the same when content and code simultaneously change?
Roland Benedetti: We're touching here as well into the bigger vision of Content Publisher. There's one workflow, which is the code workflow, Pantheon has been working for the last 15 years, basically mostly on DevOps, and web apps, but mostly on the dev side of things. And how we can manage and automate the coding approach, like not only Pantheon but of course, tools like GitHub and so on is so powerful and has become strong. So in Pantheon, we have something called Multidev, which implements the idea that when you branch your code, you can have a new environment where you can test it. And that's very powerful. And it's starting to be quite common in the industry.
But nobody managed to match this with a similar idea of branching your content: working on a new revision of your content database, mostly because of the limitations of databases. So the whole architecture we've been building with Content Publisher is actually to support this idea down the road that when we create a new branch of a corpus of content, we can execute this new branch together with a new branch of the code, which is supposed to be used for it. So that's how we basically meet content and design and code in versioning and in a unified workflow, which is a big deal, honestly, for us.
TDT [13]: Recently I read an article on Medium. This was about a guy telling about some Git-like process for content authoring, especially in the context of advocates, solicitors, who are working with Companies for mergers and acquisitions. There will be scores of pages, maybe 3000, 4000 pages to go through and there will be separate teams vetting separately. Bringing all this together would be a cumbersome task. If anything fails, the client will ultimately have to pay millions of dollars as damages and a legal tug-of-war arises. To overcome this they are building some tools to support versioning for legal matters.
Chris Yates: My observation is that Git is a great tool for comparing changes across many different documents, whether those documents are files that contain code or files that contain text. In some ways, it is ideal for people like lawyers, where it is really important to spot changes in a robust way. However, the way lawyers tend to work is by emailing each other back and forth with Microsoft Word files. They use "Track Changes" and some additional tools around that. The approach lawyers take in these situations highlights an important aspect: it's not the concept of Git itself that is challenging. Git's concept of versioning, tracking differences, and organizing many changes into one unit is quite powerful. However, Git was created by engineers for engineers, so features like merge requests, pull requests, branches, and tags are intuitive to developers but less so to lawyers or marketers.
When I was leading a marketing team, I tried introducing Git and GitLab as tools. While I found them excellent, given my background as a developer, my writers and marketers did not share the same enthusiasm. Writing in Markdown and adapting to Git-based workflows didn’t resonate well with them. This highlighted a critical point: the interface plays a significant role in usability.
Conceptually, the goals of tools like Git align well with what teams aim to achieve, but the interface needs to be more accessible. For example, the idea of a pull request could translate into a "change request" that bundles together various modifications. These might include code changes—where developers focus on details like class adjustments or syntax corrections—and content updates, such as modifications to documents, blog posts, or website elements.
Consider a campaign launch as an example. If we launch a content publisher campaign, the changes extend beyond a single action. We’re not just publishing one blog; we’re making updates across multiple areas, such as the homepage, press releases, calls to action, and other sections of the website. All these updates should ideally be grouped into one "change request." This approach allows the changes to be viewed in isolation from other activities, like daily blog posts or ongoing SEO optimization, which may be happening concurrently.
For instance, an eCommerce storefront might want to review how a design update affects a product detail page, ensuring the copy aligns with the layout. All these changes need to be examined together in a safe, controlled environment. Currently, we have this capability for code with tools like multi-dev environments on Pantheon. The goal, however, is to extend this capability to include content.
By moving away from relational databases and into a text-driven system, we can enable Git-like content comparisons. This would allow for a branching system with an interface designed for less technical users, making the process more accessible without sacrificing the robustness of Git’s functionality.
TDT [14]: Beyond content summaries and metadata suggestions, what other AI driven insights or automation are you planning to incorporate into content publisher to enhance the content creation and publishing process?
Roland Benedetti: Curating and sourcing media assets related to a story often takes a significant amount of time. It involves navigating through digital asset management systems and clicking repeatedly to find images and videos that match the story. Managing this process solely through taxonomy can be challenging. However, large language models (LLMs), combined with vector databases, now provide a way to effectively ingest and understand rich media. This allows for identifying related content without relying on specific keywords or perfectly defined taxonomy in the back end.
This presents a huge opportunity to streamline the process and eliminate much of the manual work involved in sourcing media. For instance, instead of spending time manually selecting 20 images for an article, LLMs can quickly suggest relevant options, leaving the editor to make the final selection.
Our approach to AI and generative AI is not about having the AI do the work entirely, but rather about speeding up and preparing the work. With AI, editors can quickly review suggestions and make decisions with ease. In this case, AI acts as a tool to accelerate the selection process, offering relevant proposals for images and videos. This approach is particularly valuable when dealing with considerations like copyright and usage rights, making it more practical than generating entirely new images.
TDT [15]: What is your marketing model for the Content Publisher? Will you be working bespoke with the people subscribing to the service? Or is the pricing open and transparent?
Chris Yates: That's one of the things we’re currently doing as part of the private beta—understanding where the value drivers are for this. We don’t have a finalized model yet, but the way we envision it is as an add-on to the Pantheon platform. It supports everything the Pantheon platform supports, from Drupal to WordPress to Node.js. This is something we’ll be finalizing in the coming months.
TDT [16]: Are you providing this tool directly to clients, or to companies that work with clients? I mean, will there be a bridge in between?
Chris Yates: Both. We work with a large network of partners at various scales. Some are in the digital agency space, many coming from the Drupal community that you and I know well. We also collaborate with ISVs who are creating products based on Pantheon, as well as direct commercial customers, both large and small, ranging from universities to media organizations and everything in between. We've even seen significant interest from state and local governments. Across all the areas where Pantheon is present, we've had strong interest, and we’re engaging with these groups in the first round of this private beta. While we plan to expand participation over time, we’re being deliberate in treating this as an opportunity to learn as much as possible alongside our partners and customers throughout the process.
TDT [17]: You have described content publisher as part of a post-CMS approach to publishing, emphasising a shift toward content integration rather than traditional CMS-based workflows. How do you see this evolution shaping the role of platforms like WP and Drupal?
Chris Yates: I agree with Roland's position on this, but I don’t see this as a replacement for the CMS itself. Increasingly, websites are becoming a composite of different tools. There are situations where you’ll want to create specific pages or classes of pages within a full-stack web CMS like Drupal or WordPress. At the same time, you might also want to have pages built using a different technology stack.
For example, you might use Node.js to generate pages that are programmatic in nature. If you’re creating thousands of pages from a database of highly consistent information, that’s an excellent use case—especially when the data resides outside your CMS. Over 15 years ago, one of my use cases for Drupal was actually using it as the front end. This approach differs from the decoupled method the Drupal community has discussed more recently. In that instance, Drupal acted as the front end for a vast database, such as Mars imagery, when I worked at a NASA lab. This remains a strong use case for tools like Drupal and WordPress.
However, the workflows we’ve described are more focused on content publishing. The goal is to meet people where they are and integrate them with the tools they already use rather than forcing them into less familiar systems or disrupting their workflows. For example, many users still work in Google Docs, and we shouldn’t require them to transition to Drupal for part of their workflow.
This approach focuses on connecting their existing tools to the ultimate goal of publishing their work for their audience—readers, users, or consumers. We aim to meet content authors where they are, just as we’ve already met developers by integrating with their Git environments. Similarly, as Roland mentioned earlier, we plan to connect to design tools like Figma.
I don’t view this as a post-CMS world. Instead, it reflects the reality of websites utilizing the best tools for each section. It’s about using tools that are fit for purpose and ensuring they connect seamlessly with what each member of the web team is already using.
TDT [18]: With this tool, you are trying to address the content publishing workflow. Other than content publishing, one of the major hurdles we have in web publishing industry is content distribution. We have social media, which is now trying to monitise from third-party content distribution. Then maybe some platforms like medium, they would have premium content that they are selling to subscribers. Then we have Substacks that are sort of content distribution network that makes use of newsletters. A content producer's greatest win is when their content gets to its consumers. It is still a hard nut to crack. Do you have any plans to help organisations with content distribution too?
Chris Yates: Are we also looking at content distribution? Whether that is to other websites or services like Medium or things like that? And that's one of those things that I think there is a potential to use the content publisher APIs for. It's not something that we are necessarily building for today.
Roland Benedetti: I think, you are basically on the point that there's a lot of potential using the GraphQL endpoint and the API directly for content distribution. Just to be clear, it's an open API, but it's still secure. So you can basically use it as a vehicle for gated premium content for sure. It's not like everybody could get the content from there.
You need a key, like a modern software architecture. So you can totally use it to basically send content into a distribution system, which would have gated content or which would have email or whatever.
TDT [19]: So, like Substack?
Chris Yates: Yeah, why not? We don't see our role to be the content delivery. We think actually website technology, we think marketing technology is like that's not the problem we try to solve. The problem we try to solve is the workflow.
When content is ready to go live in a channel, I think we hover the content to that channel. That's the point.
(Transcription and edits are primarily done by Alka Elizabeth. Thomas Komarickal helped with a part of it. The conversation was led by Sebin A. Jacob)
Disclaimer: Some parts of this conversation are not audible enough for reproduction due to recording mishaps. We have tried our best to reflect on the conversation as truly as possible, but we regret our shortcomings.
 Sebin A JacobFighting procrastination at every step is a journey half accomplished
Sebin A JacobFighting procrastination at every step is a journey half accomplished Alka ElizabethMy puns are intended.
Alka ElizabethMy puns are intended.
Image Attribution Disclaimer: At The Drop Times (TDT), we are committed to properly crediting photographers whose images appear in our content. Many of the images we use come from event organizers, interviewees, or publicly shared galleries under CC BY-SA licenses. However, some images may come from personal collections where metadata is lost, making proper attribution challenging.
Our purpose in using these images is to highlight Drupal, its events, and its contributors—not for commercial gain. If you recognize an image on our platform that is uncredited or incorrectly attributed, we encourage you to reach out to us at #thedroptimes channel on Drupal Slack.
We value the work of visual storytellers and appreciate your help in ensuring fair attribution. Thank you for supporting open-source collaboration!




ASK: Drupal Community Needs Your Support
View all →

Disclaimer: The information provided about the interviewee has been gathered from publicly available resources. The responsibility for the responses shared in the interview solely rests with the featured individual.
Note: The vision of this web portal is to help promote news and stories around the Drupal community and promote and celebrate the people and organizations in the community. We strive to create and distribute our content based on these content policy. If you see any omission/variation on this please reach out to us at #thedroptimes channel on Drupal Slack and we will try to address the issue as best we can.
Related Organizations
Related People

You may also like













