
Why Fault-Tolerant Hosting Is Becoming Standard for Enterprise Drupal


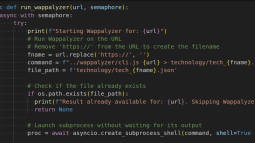
Enterprise hosting is shifting from preventing failure to managing it. In a blog post from amazee.io, Toby Bellwood describes how modern platforms are designed to expect failures and resolve them automatically before users are affected.
The post outlines how Kubernetes-based, self-healing infrastructure replaces failed containers and shifts workloads across nodes and availability zones. This reduces the impact of outages by distributing systems across multiple environments. Deployment strategies such as blue-green releases, canary testing and rolling updates further reduce risk by allowing gradual changes and quick rollbacks.
The broader shift is in how reliability is defined. Instead of focusing on stability, organisations prioritise resilience, observability and recovery. As a result, enterprise hosting becomes part of the product experience, where users expect services to remain available even when failures occur.
ASK: Drupal Community Needs Your Support
View all →
Disclosure: This content is produced with the assistance of AI.
Disclaimer: The opinions expressed in this story do not necessarily represent that of TheDropTimes. We regularly share third-party blog posts that feature Drupal in good faith. TDT recommends Reader's discretion while consuming such content, as the veracity/authenticity of the story depends on the blogger and their motives.
Note: The vision of this web portal is to help promote news and stories around the Drupal community and promote and celebrate the people and organizations in the community. We strive to create and distribute our content based on these content policy. If you see any omission/variation on this please reach out to us at #thedroptimes channel on Drupal Slack and we will try to address the issue as best we can.

Related Organizations
Related People


You may also like


















